云大&新国立| PAMIL 基于伪标签注意力的多实例学习方法
(EAAI 2025)
近日,云南大学软件学院、跨境网络空间安全教育部工程研究中心何婧副教授团队的论文 “Pseudo-label Attention-based Multiple Instance Learning for Whole Slide Image Classification” 正式发表于国际知名期刊 《Engineering Applications of Artificial Intelligence》。该论文聚焦全视野切片(WSI)病理图像分析中的关键挑战,为癌症检测和诊断提供了技术支持。研究团队成员包括云南大学软件学院的何婧、王萍、蔡静雯、唐丹、姚绍文,以及新加坡国立大学数据科学研究所的刘仁阳*(通信作者)。
全视野切片因其在病理诊断中的重要作用而备受关注。然而,WSI 的超高分辨率和弱监督标签形式让深度学习模型在处理时面临诸多难题,包括关键病灶区域难以聚焦、背景噪声干扰严重以及正负样本数量不均衡等问题。尽管多实例学习(MIL)方法已被广泛应用于这一领域,但现有方法在面对复杂病理图像时仍存在显著局限。
为了解决这些挑战,研究团队提出了一种全新的伪标签注意力多实例学习方法(Pseudo-label Attention-based Multiple Instance Learning, PAMIL)。PAMIL 通过整合伪标签生成机制和实例注意力策略,以动态加权的方式增强模型对关键病灶区域的聚焦能力,从而显著提升图像分类的整体性能(图1)。具体来说,该方法以全视野图像为输入,将其切片成多个图像块,通过自监督预训练的特征提取模块生成初始特征,并利用伪标签生成模块筛选出具有代表性的正负样本实例。随后,实例注意力机制通过构建注意力矩阵对样本进行加权,突出高权重区域并抑制背景噪声,最终通过微调策略进一步增强模型的泛化能力。
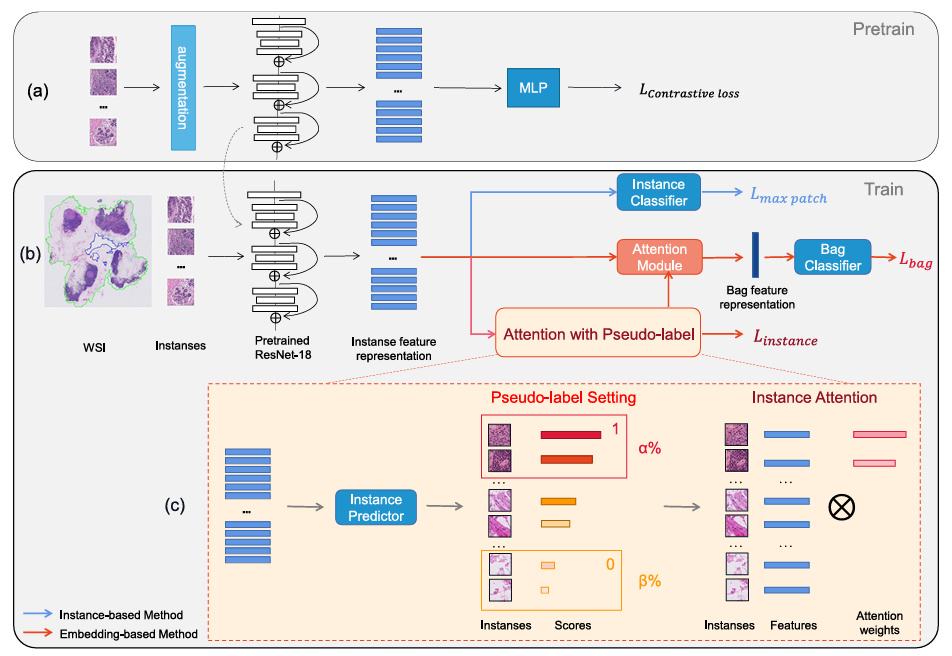
图1 PAMIL整体框架
在实验验证环节,研究团队选用了两个大规模病理图像数据集进行测试,包括 CAMELYON16(乳腺癌淋巴结转移检测)和 TCGA-NSCLC(肺癌全视野切片图像)数据集(表1和表2)。在 CAMELYON16 数据集的 20× 放大倍率下,PAMIL 模型取得了 88.8% 的准确率 和 0.916 的 AUC。在 TCGA-NSCLC 数据集中,结合微调后的 PAMIL-FT 模型,AUC 提升至 0.969,准确率达到 93.2%。进一步的消融实验表明,当去除伪标签生成模块或注意力机制后,模型性能分别下降 2.81% 和 3.88%,充分证明了这两个模块对模型性能的重要性。此外,PAMIL 模型在不同肿瘤样本比例(30%、40%、50%)设置下依然能够保持较高的稳定性,展示了其鲁棒性和广泛适用性(图2)。
表1 CAMELYON16 数据集不同方法分类性能对比
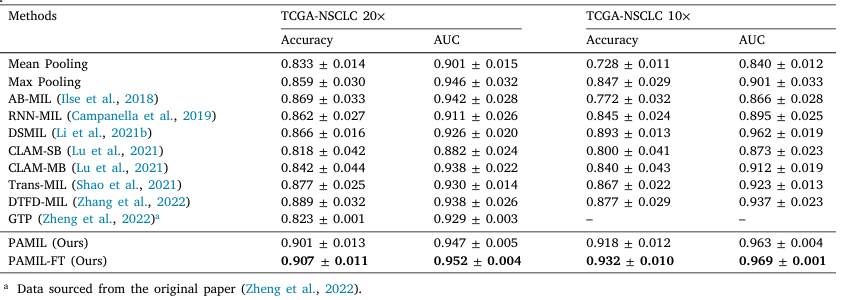
表2 TCGA-NSCLC 数据集不同方法分类性能对比
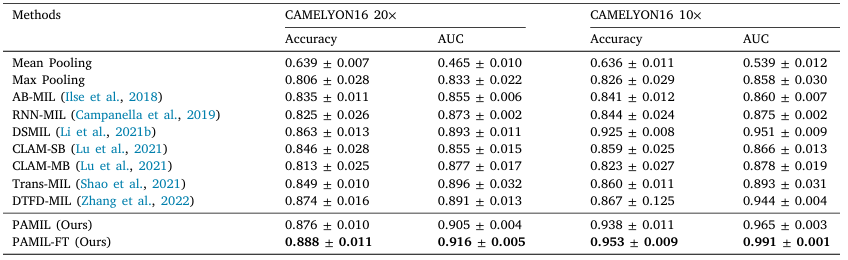
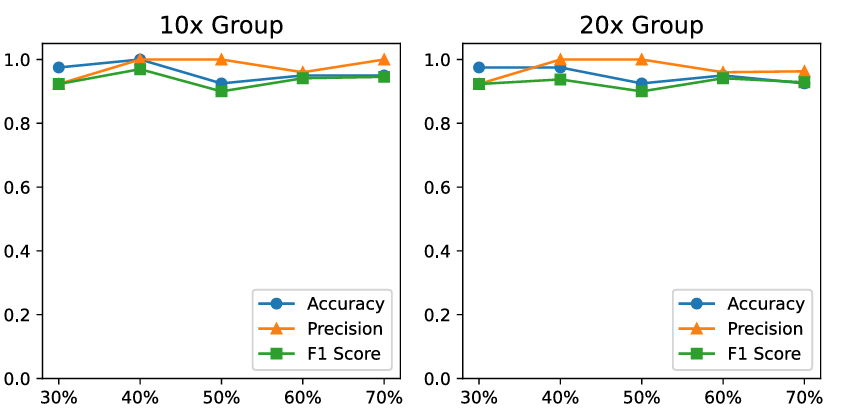
图2 不同样本比例下的准确率、精确率和 F1 分数表现
研究团队还通过生成热力图对模型的聚焦区域进行了可视化分析(图3)。结果显示,PAMIL 模型能够精准聚焦于病灶区域,其热力图与人工标注高度一致,并显著优于传统 MIL 方法。这种可视化能力不仅提高了模型的可解释性,也为后续的临床应用提供了可靠的参考。
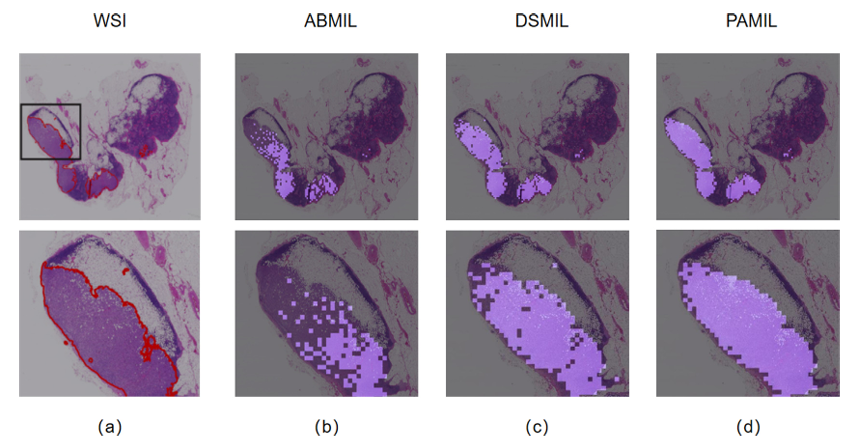
图3 CAMELYON16 数据集癌症区域的注意力图可视化
论文信息
Engineering Applications of Artificial Intelligence (EAAI) 关注人工智能在工程领域的应用和发展,现为JCR分区Q1,中科院二区TOP期刊。该期刊涵盖了各种人工智能相关的主题,如机器学习、模式识别、优化算法、数据挖掘和专家系统等,以解决实际工程问题。
供稿:何婧 云南大学软件学院
刘仁阳 新加坡国立大学数据科学研究所
论文链接:https://www.sciencedirect.com/science/article/pii/S0952197624020670
